News
How to Write High-Performance Matrix Multiply in NVIDIA CUDA Tile
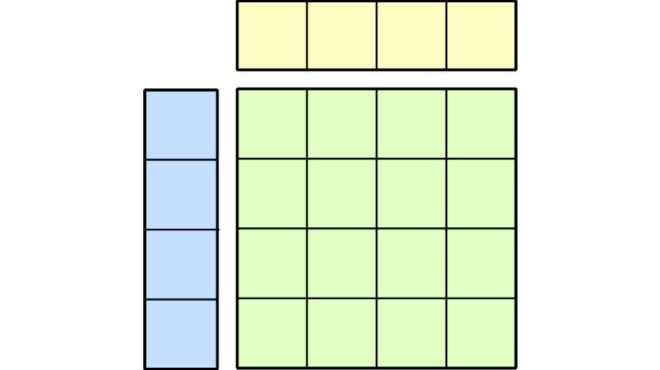 6+ hour, 49+ min ago (775+ words) This blog post is part of a series designed to help developers learn NVIDIA CUDA Tile programming for building high-performance GPU kernels, using matrix multiplication as a core example. In this post, you'll learn: Before you begin, be sure your…...
6+ hour, 49+ min ago (775+ words) This blog post is part of a series designed to help developers learn NVIDIA CUDA Tile programming for building high-performance GPU kernels, using matrix multiplication as a core example. In this post, you'll learn: Before you begin, be sure your…...
Delivering Massive Performance Leaps for Mixture of Experts Inference on NVIDIA Blackwell
1+ week, 58+ min ago (636+ words) As AI models continue to get smarter, people can rely on them for an expanding set of tasks. This leads users'from consumers to enterprises'to interact with AI more frequently, meaning that more tokens need to be generated. To serve these…...
Introducing NVIDIA BlueField-4-Powered Inference Context Memory Storage Platform for the Next
 1+ week, 1+ day ago (1289+ words) AI'native organizations increasingly face scaling challenges as agentic AI workflows drive context windows to millions of tokens and models scale toward trillions of parameters. These systems currently rely on agentic long'term memory for context that persists across turns, tools, and…...
1+ week, 1+ day ago (1289+ words) AI'native organizations increasingly face scaling challenges as agentic AI workflows drive context windows to millions of tokens and models scale toward trillions of parameters. These systems currently rely on agentic long'term memory for context that persists across turns, tools, and…...
Open-Source AI Tool Upgrades Speed Up LLM and Diffusion Models on NVIDIA RTX PCs
1+ week, 1+ day ago (576+ words) At CES 2026, NVIDIA is announcing several new updates for the AI PC developer ecosystem, including: NVIDIA collaborated with the open-source community to boost inference performance across the AI PC stack." On the diffusion front, ComfyUI optimized performance on NVIDIA GPUs…...
New Software and Model Optimizations Supercharge NVIDIA DGX Spark
1+ week, 2+ day ago (658+ words) Since its release, NVIDIA has continued to push performance of the Grace Blackwell-powered DGX Spark through continuous software optimization and close collaboration with software partners and the open-source community. These efforts are delivering meaningful gains across inference, training and creative…...
Inside the NVIDIA Rubin Platform: Six New Chips, One AI Supercomputer
1+ week, 2+ day ago (1598+ words) AI has entered an industrial phase. What began as systems performing discrete AI model training and human-facing inference has evolved into always-on AI factories that continuously convert power, silicon, and data into intelligence at scale. These factories now underpin applications…...
Accelerate AI Inference for Edge and Robotics with NVIDIA Jetson T4000 and NVIDIA JetPack 7.1
1+ week, 2+ day ago (722+ words) The module includes 1" NVENC and 1" NVDEC hardware video codec engines, enabling real-time 4K video encoding and decoding. This balanced design is built for platforms that combine advanced vision processing and I/O capabilities with power and thermal efficiency. The Jetson T4000 module…...
Real-Time Decoding, Algorithmic GPU Decoders, and AI Inference Enhancements in NVIDIA CUDA-Q QEC
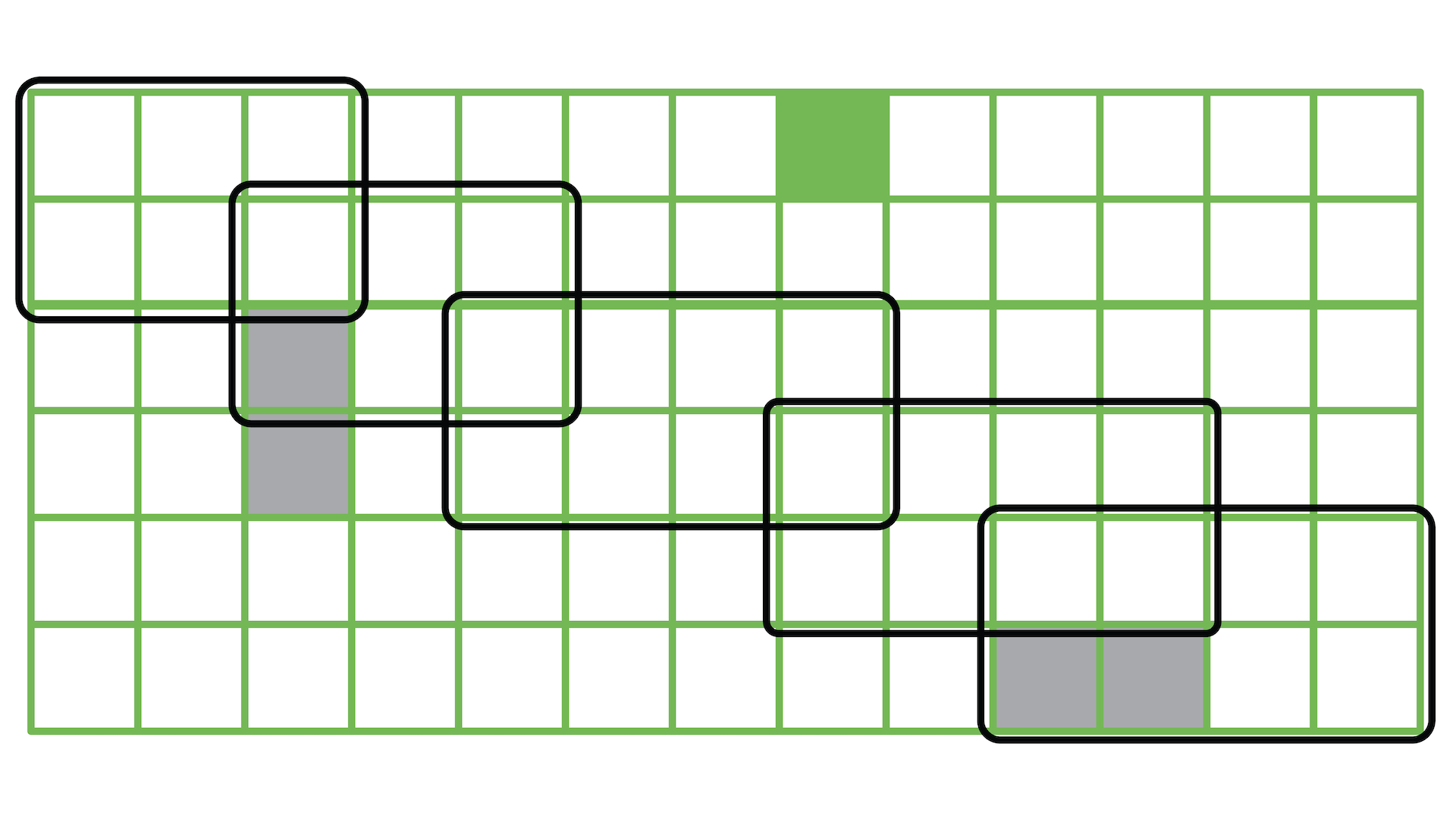 4+ week, 6+ hour ago (588+ words) To help solve these problems and enable research into better solutions, NVIDIA CUDA-Q QEC version 0.5.0 includes a range of improvements. These include support for online real-time decoding, new GPU-accelerated algorithmic decoders, infrastructure for high-performance AI decoder inference, sliding window decoder…...
4+ week, 6+ hour ago (588+ words) To help solve these problems and enable research into better solutions, NVIDIA CUDA-Q QEC version 0.5.0 includes a range of improvements. These include support for online real-time decoding, new GPU-accelerated algorithmic decoders, infrastructure for high-performance AI decoder inference, sliding window decoder…...
Migrate Apache Spark Workloads to GPUs at Scale on Amazon EMR with Project Aether
 4+ week, 8+ hour ago (566+ words) Building on this foundation, we introduce a smart and efficient way to migrate existing CPU-based Spark workloads running on Amazon Elastic MapReduce (EMR). Project Aether is an NVIDIA tool engineered to automate this transition. It works by taking existing CPU…...
4+ week, 8+ hour ago (566+ words) Building on this foundation, we introduce a smart and efficient way to migrate existing CPU-based Spark workloads running on Amazon Elastic MapReduce (EMR). Project Aether is an NVIDIA tool engineered to automate this transition. It works by taking existing CPU…...
Solving Large-Scale Linear Sparse Problems with NVIDIA cuDSS
 4+ week, 9+ hour ago (966+ words) You can leverage your CPU/GPU using hybrid memory mode to run larger problems that otherwise would not fit in a single GPU memory, or run a workload across multiple GPUs, or even scale to multiple nodes effortlessly. This blog…...
4+ week, 9+ hour ago (966+ words) You can leverage your CPU/GPU using hybrid memory mode to run larger problems that otherwise would not fit in a single GPU memory, or run a workload across multiple GPUs, or even scale to multiple nodes effortlessly. This blog…...